


DeepSeek 开源 FlashMLA:高效 MLA 解码新时代
今天是 #OpenSourceWeek的第一天,DeepSeek 发布了一个重量级开源项目——FlashMLA!作为一名关注 AI 计算优化的自媒体人,我必须跟大家聊聊这个项目,它或许会对大模型推理带来革命性的提升。
🔍 FlashMLA 是什么?
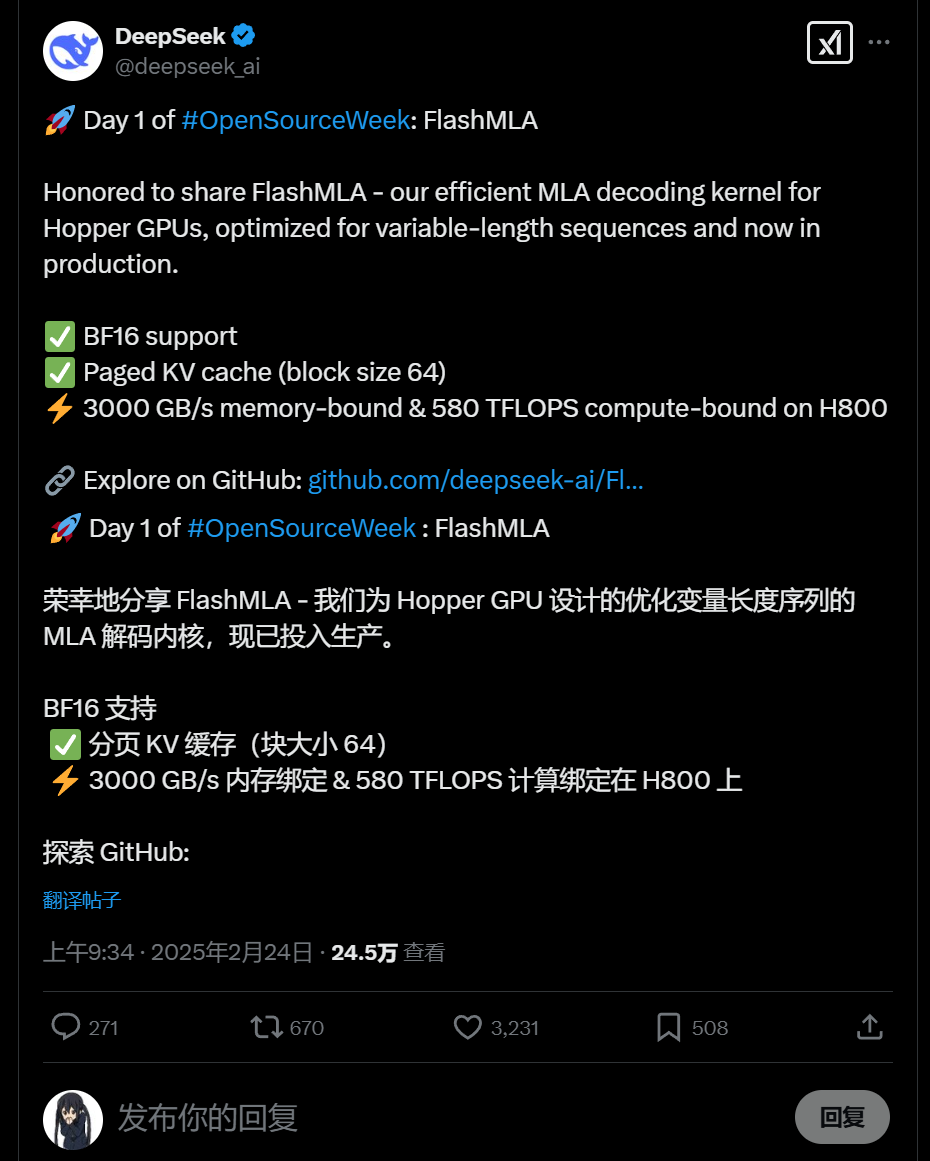
FlashMLA 是一个 高效的 MLA(Multi-Head Latent Attention)解码内核,专为 Hopper GPU 设计,优化了变长序列推理,并已投入生产环境。其亮点包括:
✅ BF16 支持,提供更高效的数值计算能力,减少计算精度损失,同时优化存储带宽使用率
✅ 分页 KV 缓存(block size 64) ,采用 高效的分块存储策略,减少长序列推理时的显存占用,提高缓存命中率,从而提升计算效率
✅ 极致性能优化,在 H800 GPU 上,FlashMLA 通过优化访存和计算路径,达到了 3000 GB/s 内存带宽 & 580 TFLOPS 计算能力,最大化利用 GPU 资源,减少推理延迟
这意味着什么?简单来说,FlashMLA 不仅能够加速 Transformer 推理,还能够 降低显存占用、减少计算开销,使得大规模 AI 模型的推理变得更快、更高效,非常适用于 大模型推理和高并发任务!
🎯 FlashMLA 能做什么?
这个项目最直接的应用场景是 大规模 AI 模型推理,尤其是在 NLP、语音识别、推荐系统 等领域,带来显著优化:
- 大语言模型(LLM)推理:加速 Transformer 计算,提高推理吞吐量
- 机器翻译(MT) :更快的文本处理能力,减少计算资源消耗
- 语音识别(ASR) :优化长文本推理,降低推理延迟
- 推荐系统(RecSys) :高效处理大规模数据,提高推荐精准度
作为一名自媒体人,我认为 FlashMLA 的发布意味着未来 大模型推理的计算效率将迎来新的突破,尤其是对那些依赖 GPU 计算的企业和开发者来说,简直是福音!
🚀 如何体验 FlashMLA?
想试试看 FlashMLA 的威力?这里有完整的开源地址:GitHub 项目链接!
📌 快速安装:
python setup.py install
📊 性能测试:
python tests/test_flash_mla.py
FlashMLA 受到 FlashAttention 2&3 和 CUTLASS 项目的启发,并结合了最新的 GPU 加速优化技术。
💡 作为 AI 领域的观察者,我认为 FlashMLA 绝对是 2025 年 AI 计算优化的重要突破之一!欢迎大家一起探索,共同推动 AI 计算性能的新高度!如果你也对 AI 加速技术感兴趣,不妨 Star⭐ 一下支持这个开源项目!







