


Python爬虫 | 淘票票评论抓取
利用Python解密 sign及自动获取Cookies和Token的评论抓取实现
背景:评论数据抓取的挑战
淘票票作为一个知名的电影票务平台,其评论数据往往对用户公开,但为了防止未经授权的数据抓取,淘票票引入了多重反爬机制,比如sign加密、cookies验证以及复杂的token生成机制等。因此,实现自动化的数据获取需要绕过这些保护机制。在本文中,我们展示了如何利用Python实现以下目标:
- 自动获取
cookies和token - 使用MD5对
sign加密字符串进行解密,以构造合法的API请求 - 自动循环分页并抓取评论数据
技术实现细节
第一步:进行 sign断点调试和逆向解密
首先,打开淘票票的网页,调整到小尺寸模式,因为在大尺寸下没有看到影评区域,调整好之后我们打开任意一个电影的影评区
不难看出当评论加载的时候,前端向后端提交了一个 Get请求
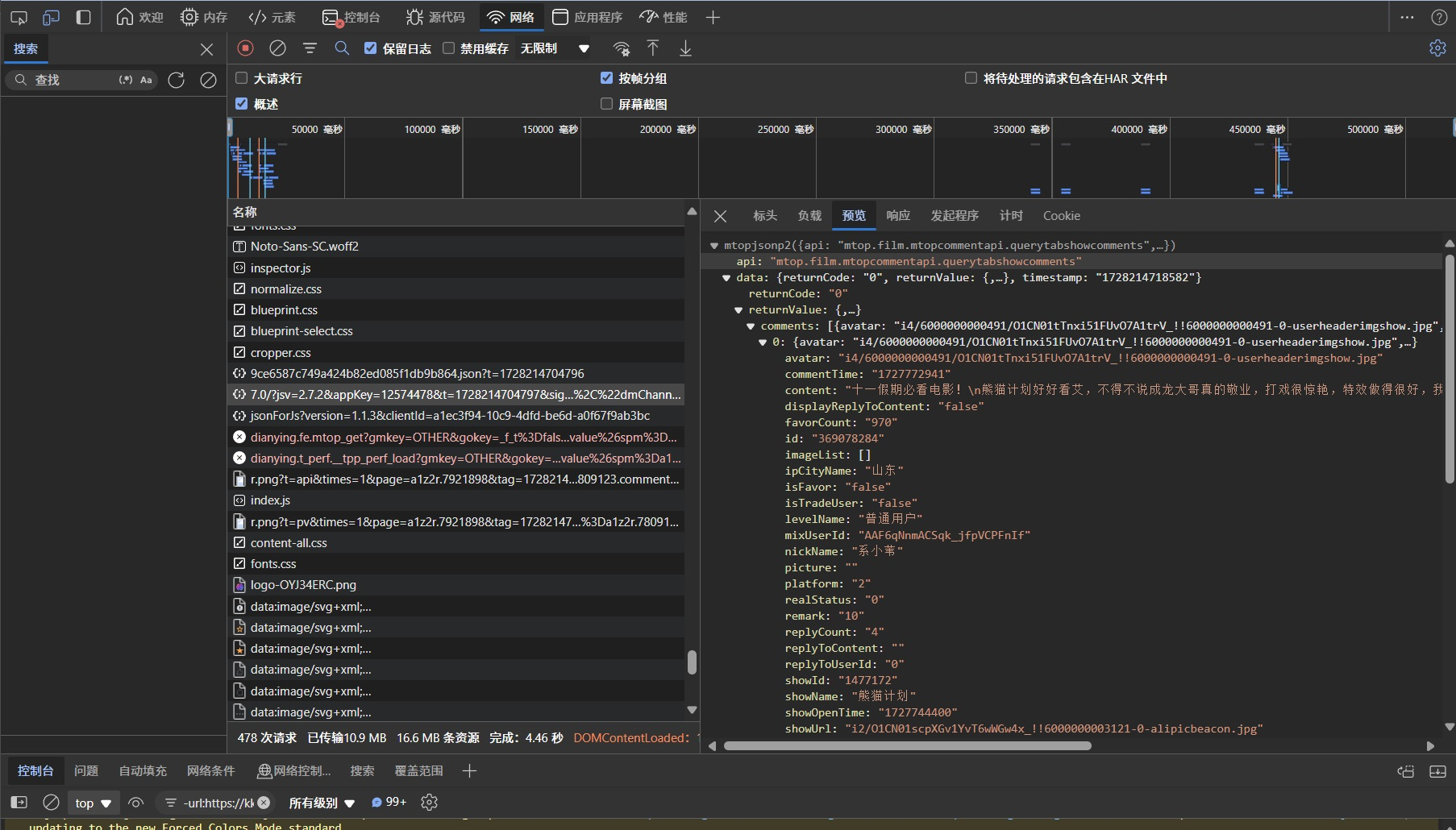
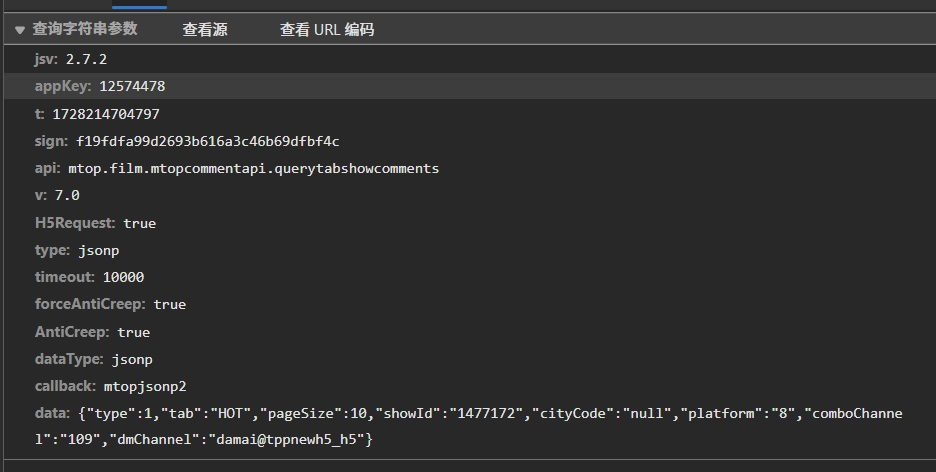
为了生成合法的请求,我们首先需要解密淘票票使用的 sign加密逻辑,通过浏览器搜索大法,我精确的定位到了 sign的加密部位,不难发现 n.token + "&" + u + "&" + s + "&" + r.data,sign的生成涉及到对时间戳、token和请求数据进行MD5加密,进而得到一个唯一的签名,
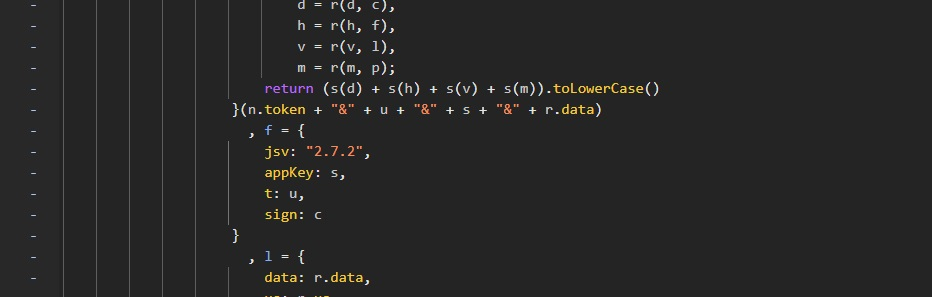
通过手动复制参数进行断点调试,得出结果与浏览器生成 sign无异,证明猜想正确,进行代码编写,进行md5加密,传入data数据,传出md5加密后的数据
import hashlib
def md5_encrypt(data):
return hashlib.md5(data.encode('utf-8')).hexdigest().lower()
第二步:自动获取Cookies和Token
当然既然实现自动化了,就不能只有简单的需要你手动打断点进行调试的自动化,通过访问平台的评论接口首先需要获取相应的 cookies和 token。这些验证信息会在每一段时间访问时候发生改变。为此,我们向平台的 POST接口发送一次 GET请求来寄希望于平台为你补cookies,不负众望,平台对cookies进行了补全,使用了 requests库的Session对象来管理会话和 cookies信息
import requests
import time
def get_token_and_cookies(session, app_key, max_retries=5, delay=3):
for attempt in range(1, max_retries + 1):
try:
t = str(int(time.time() * 1000))
initial_url = (f"https://acs.m.taopiaopiao.com/h5/mtop.film.mtopcommentapi.querytabshowcomments/7.0/"
f"?jsv=2.7.2&appKey={app_key}&t={t}&api=mtop.film.mtopcommentapi.querytabshowcomments"
f"&v=7.0&H5Request=true&type=jsonp&timeout=10000&forceAntiCreep=true&AntiCreep=true&dataType=jsonp")
initial_headers = {
'user-agent': 'Mozilla/5.0 ...'
}
response = session.get(initial_url, headers=initial_headers, verify=False, timeout=10)
if response.status_code == 200:
cookies = session.cookies.get_dict()
token_cookie = cookies.get('_m_h5_tk')
if token_cookie:
token = token_cookie.split('_')[0]
return token, cookies
except requests.exceptions.RequestException as e:
print(f"尝试第 {attempt} 次请求发生错误: {e}")
time.sleep(delay)
return None, {}
在此步骤中,我们发送了一个 GET请求,以便从服务端获取 cookies和 token,这些信息是后续评论抓取请求的必要验证信息。通过对响应的cookie进行解析,我们提取出 _m_h5_tk,_m_h5_tk是token和时间戳的结合数据。为了防止服务器拒绝补全请求, 设置了多次请求来进行获取cookies。
第三步:抓取评论数据
获取到 token和 cookies后,便可以正式发起评论抓取请求。每个请求的 sign是由 token、时间戳、应用密钥(app_key)和请求体组成的字符串,通过MD5加密得到。
import json
import urllib.parse
def run(app_key, total_pages, showId):
session = requests.Session()
token, cookies = get_token_and_cookies(session, app_key)
if not token:
print("无法获取 token,退出脚本")
return
lastId = None
all_results = []
headers = {'cookie': '; '.join([f"{k}={v}" for k, v in cookies.items()]), ...}
for page_number in range(1, total_pages + 1):
data_dict = {
"type": 1,
"tab": "GOOD",
"pageSize": 10,
"showId": showId,
}
if lastId:
data_dict["lastId"] = lastId
data_json = json.dumps(data_dict, ensure_ascii=False)
encoded_data = urllib.parse.quote(data_json)
t = str(int(time.time() * 1000))
sign_input = f"{token}&{t}&{app_key}&{data_json}"
sign = md5_encrypt(sign_input)
url = (f"https://acs.m.taopiaopiao.com/h5/mtop.film.mtopcommentapi.querytabshowcomments/7.0/"
f"?appKey={app_key}&t={t}&sign={sign}&data={encoded_data}")
response = session.get(url, headers=headers, verify=False, timeout=10)
if response.status_code == 200:
response_text = response.text
json_match = re.search(r'^[^(]*\((.*)\)$', response_text, re.S)
if json_match:
json_data = json.loads(json_match.group(1))
comments = json_data.get('data', {}).get('returnValue', {}).get('comments', [])
if comments:
lastId = comments[-1].get('id')
for comment in comments:
all_results.append({
'昵称': comment.get('nickName', ''),
'评论内容': comment.get('content', ''),
'城市': comment.get('ipCityName', '')
})
在此步骤中,我们构造了评论抓取的请求。每一页请求都会包含上一页的最后一个 lastId,从而实现分页抓取。每次请求后,我们解析返回的JSON数据并提取出评论内容。
我们设计了分页机制以确保可以获取尽可能多的评论数据,这样的分页请求可以一直持续,直到到达指定的总页数。分页的实现通过 lastId来追踪已经获取的评论,确保不会重复抓取,同时使得请求的连续性和逻辑更加简洁。
结论
通过上述流程,我们可以实现评论数据的自动化抓取,包括获取必要的验证信息如 token和 cookies,以及使用MD5加密生成合法的请求 sign。数据抓取的成功与否与技术实现的细节息息相关,例如请求的时机、反爬虫机制的应对策略、以及对数据结构的正确理解。
代码开源
代码是完全开源的,欢迎有需要的小伙伴学习,感谢大佬指正一二。
import os
import requests
import pandas as pd
import json
import time
import hashlib
import urllib.parse
import re
from dotenv import load_dotenv
def md5_encrypt(data):
return hashlib.md5(data.encode('utf-8')).hexdigest().lower()
def get_token_and_cookies(session, app_key, max_retries=5, delay=3):
for attempt in range(1, max_retries + 1):
try:
t = str(int(time.time() * 1000))
initial_url = (
f"https://acs.m.taopiaopiao.com/h5/mtop.film.mtopcommentapi.querytabshowcomments/7.0/"
f"?jsv=2.7.2&appKey={app_key}&t={t}&api=mtop.film.mtopcommentapi.querytabshowcomments"
f"&v=7.0&H5Request=true&type=jsonp&timeout=10000&forceAntiCreep=true&AntiCreep=true&dataType=jsonp"
)
initial_headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,pl;q=0.5',
'referer': 'https://m.taopiaopiao.com/',
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) '
'AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 '
'Mobile/15E148 Safari/604.1 Edg/131.0.0.0'
}
print(f"尝试第 {attempt} 次获取 cookies 和 token...")
response = session.get(initial_url, headers=initial_headers, verify=False, timeout=10)
if response.status_code == 200:
cookies = session.cookies.get_dict()
print("获取到的 cookies:", cookies)
token_cookie = cookies.get('_m_h5_tk')
if token_cookie:
token = token_cookie.split('_')[0]
print(f"提取到的 token: {token}")
return token, cookies
else:
print("未找到 _m_h5_tk cookie")
else:
print(f"初始请求失败,状态码: {response.status_code}")
except requests.exceptions.RequestException as e:
print(f"第 {attempt} 次请求发生错误: {e}")
if attempt < max_retries:
print(f"等待 {delay} 秒后重试...")
time.sleep(delay)
else:
print("达到最大重试次数,无法获取 token。")
return None, {}
def run(app_key=None, total_pages=10, showId=None):
requests.packages.urllib3.disable_warnings(requests.packages.urllib3.exceptions.InsecureRequestWarning)
session = requests.Session()
app_key = app_key
total_pages = total_pages
token, cookies = get_token_and_cookies(session, app_key)
if not token:
print("无法获取 token,退出脚本")
return
lastId = None
all_results = []
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6,pl;q=0.5',
'cookie': '; '.join([f"{k}={v}" for k, v in cookies.items()]),
'referer': 'https://m.taopiaopiao.com/',
'sec-fetch-dest': 'script',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 16_6 like Mac OS X) '
'AppleWebKit/605.1.15 (KHTML, like Gecko) Version/16.6 '
'Mobile/15E148 Safari/604.1 Edg/131.0.0.0'
}
for page_number in range(1, total_pages + 1):
data_dict = {
"type": 1,
"tab": "GOOD", # "GOOD" 表示好评,"HOT" 表示热评, "BAD" 表示差评
"pageSize": 10,
"showId": showId,
"cityCode": "null",
"platform": "8",
"comboChannel": "109",
"dmChannel": "damai@tppnewh5_h5"
}
if lastId:
data_dict["lastId"] = lastId
else:
data_dict["lastId"] = ""
data_json = json.dumps(data_dict, ensure_ascii=False)
encoded_data = urllib.parse.quote(data_json)
callback = f"mtopjsonp{page_number}"
t = str(int(time.time() * 1000))
sign_input = f"{token}&{t}&{app_key}&{data_json}"
sign = md5_encrypt(sign_input)
url = (
f"https://acs.m.taopiaopiao.com/h5/mtop.film.mtopcommentapi.querytabshowcomments/7.0/"
f"?jsv=2.7.2&appKey={app_key}&t={t}&sign={sign}"
f"&api=mtop.film.mtopcommentapi.querytabshowcomments&v=7.0&H5Request=true"
f"&type=jsonp&timeout=10000&forceAntiCreep=true&AntiCreep=true"
f"&dataType=jsonp&callback={callback}&data={encoded_data}"
)
print(f"\n第 {page_number} 页请求 URL:", url)
try:
response = session.get(url, headers=headers, verify=False, timeout=10)
if response.status_code == 200:
response_text = response.text
print(f"第 {page_number} 页原始响应:", response_text[:100] + '...')
try:
json_match = re.search(r'^[^(]*\((.*)\)$', response_text, re.S)
if json_match:
json_data = json.loads(json_match.group(1))
print(f"第 {page_number} 页解析后的数据:", json_data)
comments = json_data.get('data', {}).get('returnValue', {}).get('comments', [])
if comments:
lastId = comments[-1].get('id')
for comment in comments:
all_results.append({
'昵称': comment.get('nickName', ''),
'评论内容': comment.get('content', ''),
'城市': comment.get('ipCityName', '')
})
else:
print(f"第 {page_number} 页响应格式不正确,无法提取 JSON 数据。")
except (json.JSONDecodeError, AttributeError) as e:
print(f"第 {page_number} 页 JSON 解析错误: {e}")
except KeyError as e:
print(f"第 {page_number} 页缺少键: {e}")
else:
print(f"第 {page_number} 页请求失败,状态码: {response.status_code}")
except requests.exceptions.SSLError as e:
print(f"第 {page_number} 页 SSL 错误: {e}")
except requests.exceptions.RequestException as e:
print(f"第 {page_number} 页请求错误: {e}")
except Exception as e:
print(f"第 {page_number} 页发生错误: {e}")
time.sleep(1)
if all_results:
df = pd.DataFrame(all_results)
df.to_excel('comments_all.xlsx', index=False)
print("所有评论已保存到 comments_all.xlsx")
else:
print("未收集到任何评论数据。")
if __name__ == "__main__":
load_dotenv()
showId = os.environ.get("SHOW_ID")
app_key = os.environ.get("APP_KEY")
total_pages = int(os.environ.get("TOTAL_PAGES"))
run(app_key, total_pages, showId)







